今天带来一篇Martin大神的新作,CVPR19预定,基本上看是结合了IoUNet和深度回归网络, 前者用于精细定位和尺度估计,后者用于粗略定位提供候选框。欢迎与我讨论~👉论文地址
1. 主要贡献
- 将目标跟踪分为目标分类和目标评价两个网络部分,前者分类用于粗定位,后者用于精细定位,即两阶段跟踪;
- 目标估计网络使用了ECCV18的IoUNet结构,基于大数据集离线训练,训练时最大化与gt的IoU;
- 目标分类网络使用了深度回归网络结构,由2层卷积层构成,在线训练,根据输出的map选择候选框交给目标估计网络,并且提出了新的快速在线训练方法;
- 性能超过了DaSiamese,GPU下达到30fps。
2. 方法动机
首先说为什么跟踪要把分类和估计分开,因为分类主要用来判断某个位置目标是否存在,而对目标的状态并不敏感,目标状态在跟踪中简化为2 D位置和目标框的长宽,这个是目标评价做的事,所以将跟踪框架分成两个任务模块有助于提高整体的性能。 基于CF的跟踪器可以说是一个不错的分类器,它会输出一个响应图,根据最大响应判断目标最可能存在的位置,但是这种方法不能完全估计目标的状态 ,比如尺度,所以尺度估计一般会使用额外的分类器进行估计。而目标的精确估计需要大量的先验信息,因为如形变这类目标变化是难以单靠跟踪图像的信息进行估计的。 所以作者认为SiameseRPN的成功主要依赖于大量的离线训练,但是Siamese方法大部分受限于分类的性能,因为这类方法没有在线训练的过程,而CF方法是有的,所以没有在线训练 导致它不能很好的应对跟踪中的干扰,或者说相似的目标,模型更新也只能部分解决这个问题。所以作者提出了一个在线训练的分类器和 一个离线训练的评价网络,联合起来解决目标跟踪问题 ,其实和检测很像了,就是一个两阶段的跟踪框架。
3. 方法
3.1 总体结构
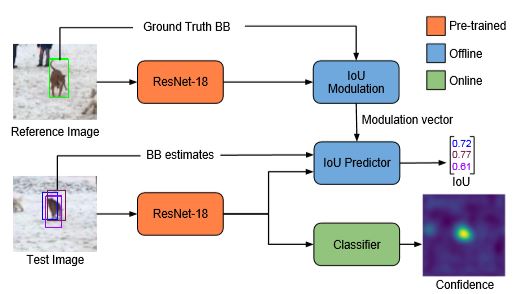 如图可以看到分类网络和评价网络被整合到了一个网络框架中,两个任务使用了同样的主干网络,即ResNet-18,这部分是在ImageNet
上预训练好的然后再跟踪中第一帧fine-tune。目标评价使用离线训练的IoU预测模块,在大量的数据集上训练,数据是王道啊
,这一块有四个输入,分别是参考帧的bounding box(简称bb)及主干网络提出的特征和测试帧的候选bb及特征,
它会输出候选框对应的IoU值,最终的bb使用梯度下降法最大化IoU值得到。
如图可以看到分类网络和评价网络被整合到了一个网络框架中,两个任务使用了同样的主干网络,即ResNet-18,这部分是在ImageNet
上预训练好的然后再跟踪中第一帧fine-tune。目标评价使用离线训练的IoU预测模块,在大量的数据集上训练,数据是王道啊
,这一块有四个输入,分别是参考帧的bounding box(简称bb)及主干网络提出的特征和测试帧的候选bb及特征,
它会输出候选框对应的IoU值,最终的bb使用梯度下降法最大化IoU值得到。
分类网络是在线训练的一个全卷积结构,用于增强分类器区别目标和场景中其他物体的判别力,输入当前帧搜索域的特征,它会输出目标位置的置信图。 。另外作者认为通过SGD方法训练不是最优的,提出了一套基于共轭梯度和牛顿高斯的方法进行优化,真厉害!3.2 基于IoUNet的网络
3.2.1 网络结构
一个简单的评价模块即传统的bb回归的方法,给一个粗略的目标状态返回一个更加准确的目标状态。ECCV18的IoUNet训练时预测 bb和gt的IoU,然后测试时直接最大化IoU得到一个更加准确的目标状态,有兴趣的同学可以去读一读。Martin就直接把这个想法用过来 具体来说,IoUNet输入一张图的深度特征和一些候选bb(中心坐标和长宽),然后用PrPooling层得到固定size的bb区域的特征 ,这里PrPool是一个可连续的操作,即对bb坐标可导,如此可以通过梯度下降最大化IoU得到最佳的bb。
由于跟踪任务的目标是没有类别一说的,所以和检测任务不同,这里的IoU模块需要针对目标而不是针对类别进行训练,作者认为 IoU预测模块是一个高层语义的模块所以仅仅使用视频第一帧训练是不合理的,所以需要离线训练得到一个泛化能力强的IoU预测模块。 下面关键来了,由于跟踪我们事先不知道目标是谁,需要在测试时给定,所以难点在于IoU模块如何利用好给定目标的参考帧的信息,作者进行了很多尝试 ,发现Siamese的结构不错,于是就用了类似的叫做基于调制的网络来预测给定参考帧的任意目标的IoU。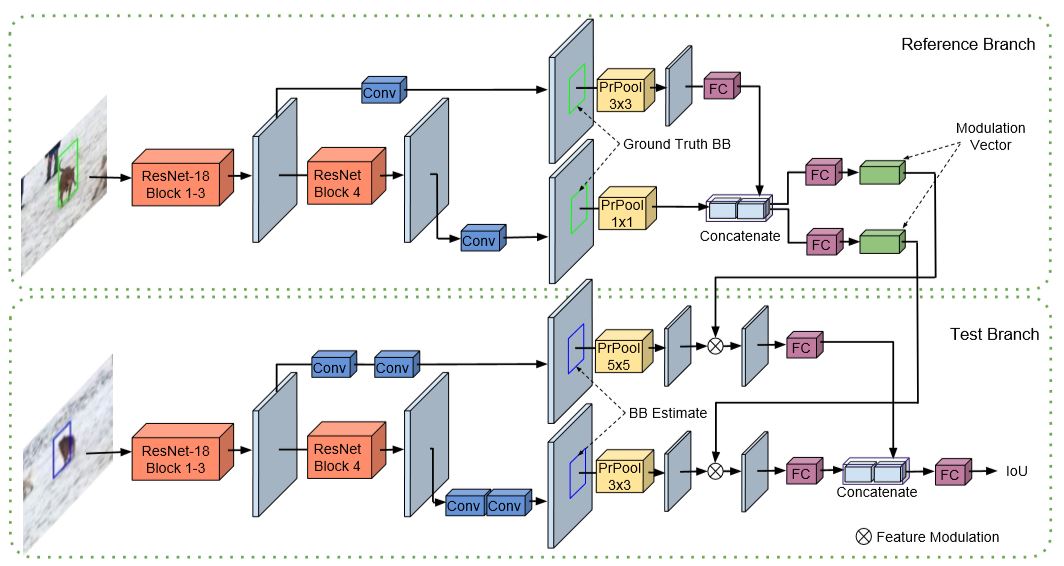 如图,这部分网络设计的挺复杂,分为上下两部分,上半部利用参考帧生成调制向量给下半部测试帧的网络进行调制。
两支的输入特征网络都是一致的。上半部分提出的是参考帧$x_0$的参考目标$B_0$的特征,输出一个正数的D维的调制向量c,D对应特征层数。
而在测试帧x时,网络部分发生了变化,主干网络提出的特征后多接了一层卷积层,相应的后面pooling也变大了,之后用调制向量
对特征的每一通道做了加权处理,即赋予了参考帧的信息,调制后的特征再被送给IoU预测模块g,即三个全连接层后输出IoU,
那么公式表达对一个bb,B的IoU即$IoU(B)=g(c(x_0,B_0)\cdot z(x,B))$。
如图,这部分网络设计的挺复杂,分为上下两部分,上半部利用参考帧生成调制向量给下半部测试帧的网络进行调制。
两支的输入特征网络都是一致的。上半部分提出的是参考帧$x_0$的参考目标$B_0$的特征,输出一个正数的D维的调制向量c,D对应特征层数。
而在测试帧x时,网络部分发生了变化,主干网络提出的特征后多接了一层卷积层,相应的后面pooling也变大了,之后用调制向量
对特征的每一通道做了加权处理,即赋予了参考帧的信息,调制后的特征再被送给IoU预测模块g,即三个全连接层后输出IoU,
那么公式表达对一个bb,B的IoU即$IoU(B)=g(c(x_0,B_0)\cdot z(x,B))$。3.2.1 训练
根据IoU表达式,这个部分是可以通过标记的图片对进行端到端训练的,作者使用了LaSOT和trackingNet数据集上采集的图片对,还使用了coco数据集进行数据扩增 ,采用了和DaSiamese类似的方法,在参考帧上,提取了目标周围的5倍大小的方形区域作为输入,测试帧则是将图片做了位置和尺度的偏移扰动 来模仿跟踪场景,每一个图片对生成16个候选bb,这是由gt加上高斯噪声生成的,并且设定bb和gt最小的IoU为0.1,使用图像模糊和色彩扰动 进行数据扩增,IoU最终归一化到-1和1之间。训练的时候主干网络是不更新的。
3.3 分类网络
这部分结构很简单,由两层卷积层构成,主要用于粗略定位所以不需要更深的网络,说是分类网络其实更像回归,类似深度回归跟踪的思想,用卷积操作回归出一个以目标为中心的高斯label, 写出函数即
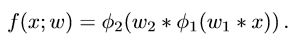 和CF方法类似写出目标函数即
和CF方法类似写出目标函数即
 w则是卷积核的参数,那么如何在线学习,传统的随机梯度下降的收敛速度太慢了,而Martin是一个对速度要求很高的男人绝对不允许所以设计了更快的算法,
把正则项的表达和残差的表达统一起来,$r_j(w)=\sqrt \gamma_j(f(x_j;w)-y_j)$,这里j从1到m代表每个位置,正则项
$r_{m+k}(w)=\sqrt \lambda_k w_k$,这里k取1和2即两层的卷积。那么loss可以写成更简单的形式$L(w)=|r(w)|^2$,根据高斯牛顿近似忽略二阶微分,
首先在$w+\Delta w$处对r一阶
泰勒展开$r(w+\Delta w)\approx r_w + J_w \Delta w$,那么$L(w+\Delta w)$即为下式
w则是卷积核的参数,那么如何在线学习,传统的随机梯度下降的收敛速度太慢了,而Martin是一个对速度要求很高的男人绝对不允许所以设计了更快的算法,
把正则项的表达和残差的表达统一起来,$r_j(w)=\sqrt \gamma_j(f(x_j;w)-y_j)$,这里j从1到m代表每个位置,正则项
$r_{m+k}(w)=\sqrt \lambda_k w_k$,这里k取1和2即两层的卷积。那么loss可以写成更简单的形式$L(w)=|r(w)|^2$,根据高斯牛顿近似忽略二阶微分,
首先在$w+\Delta w$处对r一阶
泰勒展开$r(w+\Delta w)\approx r_w + J_w \Delta w$,那么$L(w+\Delta w)$即为下式
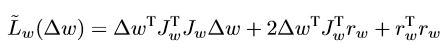 其中$J_w$代表r对w的雅可比矩阵,详细可以参考高斯牛顿法解非线性二次函数问题。我们需要的变量就是$\Delta w$用于更新w,可以直接令
$L(w+\Delta w)-L(w)$对$\Delta w$求导得到$\Delta w$的解析解,即$-\left(J_w^T J_w\right)^{-1}J_w^T r_w$,
这里为了避免求逆且$J_w^T J_w$正定,可以使用共轭梯度下降法解,这里作者为了简化求解过程,利用了深度学习框架的反传函数巧妙实现了这一过程,
整体算法如下
其中$J_w$代表r对w的雅可比矩阵,详细可以参考高斯牛顿法解非线性二次函数问题。我们需要的变量就是$\Delta w$用于更新w,可以直接令
$L(w+\Delta w)-L(w)$对$\Delta w$求导得到$\Delta w$的解析解,即$-\left(J_w^T J_w\right)^{-1}J_w^T r_w$,
这里为了避免求逆且$J_w^T J_w$正定,可以使用共轭梯度下降法解,这里作者为了简化求解过程,利用了深度学习框架的反传函数巧妙实现了这一过程,
整体算法如下
 很明显包含两层循环,大循环利用高斯牛顿法更新w,小循环利用共轭梯度法求解$\Delta w$,详细过程就不展开了,
只说说如何利用反传函数,令s是一个标量函数,v为变量,那么有$BackProp(s,v)=\frac{\partial s}{\partial v}$,
那么类似的$BackProp(r^T u,w)=J_w^T u$,其它的类推。
很明显包含两层循环,大循环利用高斯牛顿法更新w,小循环利用共轭梯度法求解$\Delta w$,详细过程就不展开了,
只说说如何利用反传函数,令s是一个标量函数,v为变量,那么有$BackProp(s,v)=\frac{\partial s}{\partial v}$,
那么类似的$BackProp(r^T u,w)=J_w^T u$,其它的类推。3.4 在线跟踪细节
特征提取部分都用的ResNet-18网络,分类网络只用了block4的特征,评价网络3和4都用了。
分类网络第一层卷积核是1*1的用于降维到64,第二层4*4的,只输出一层特征,激活函数使用的是PELU,优点是在0处也可导。 第一帧使用了数据扩增,第一层卷积参数仅在初始帧优化,后面只优化第二层,trick太多了,还使用了困难样本挖掘。 评价网络部分估计目标的位置和尺度,首先根据分类网络的置信图找到最大置信点,即粗略的候选目标区,结合上一帧的尺度生成初始 bb,理论上只用一个bb就可以了,但是多多益善嘛,所以加了噪声后又生成9个,10个bb都给IoUNet预测模块,对每个bb,5次梯度下降 迭代最大化IoU得到最优bb,最后取3个最高IoU值的bb的平均作为最终预测结果,这里面的调制向量仅仅是第一帧计算出来的,也就是说参考帧分支 仅在第一帧用,后面就不用了,参考帧就是初始化帧。4. 实验
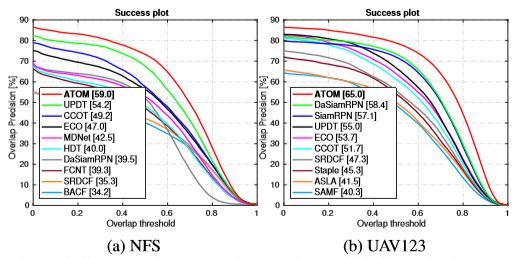
Pytorch上进行的实验,GPU速度30fps,测了4个数据库,NfS,UAV123,TrackingNet和Vot18,VOT18超过第一1%,UAV123超过DaSiamese6.6% ,超过ECO12%,相当惊人。
作者探究了一下评价网络设计的不同结构的性能,大家可以看看,Siamese结构也有不错的性能。总结:CVPR19的Oral预定。